We are happy to announce that our paper entitled “Pointy – A Lightweight Transformer for Point
Cloud Foundation Models” was presented during 22nd International Conference Advanced Concepts for Intelligent Vision Systems (ACIVS 2025).
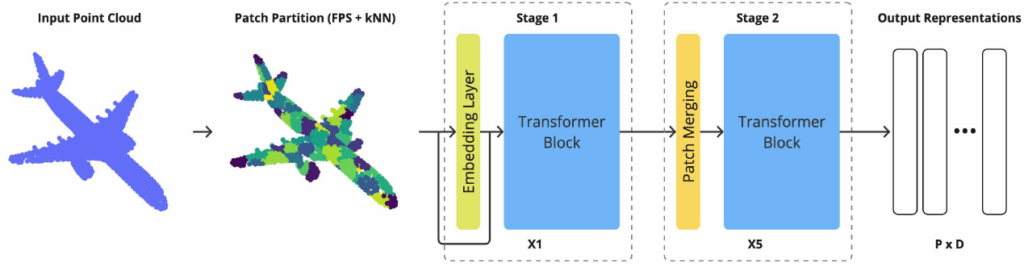
Foundation models for point cloud data have recently grown in capability, often leveraging extensive representation learning from language or vision. In this work, we take a more controlled approach by
introducing a lightweight transformer-based point cloud architecture. In contrast to the heavy reliance on cross-modal supervision, our model is trained only on 39k point clouds – yet it outperforms several larger foundation models trained on over 200k training samples. Interestingly, our method approaches state-of-the-art results from models that have seen over a million point clouds, images, and text samples, demonstrating the value of a carefully curated training setup and architecture. To ensure
rigorous evaluation, we conduct a comprehensive replication study that standardizes the training regime and benchmarks across multiple point cloud architectures. This unified experimental framework isolates the impact of architectural choices, allowing for transparent comparisons and
highlighting the benefits of our design and other tokenizer-free architectures. Our results show that simple backbones can deliver competitive results to more complex or data-rich strategies.
[1] K. Szafer, M. Kraft, D. Belter, Pointy – A Lightweight Transformer for Point Cloud Foundation Models, Advanced Concepts for Intelligent Vision Systems: 22nd International Conference, ACIVS 2025, Tokyo, Japan, July 28–30, 2025, Proceedings / red. Jacques Blanc-Talon, Patrice Delmas, Hiroki Takahashi, Minami Yasuhiro – Cham, Switzerland : Springer, 2026 – p. 341-352, (CORE B)

{kind=link}